

Edge computing is expanding dramatically as organizations rush to realize the benefits in latency, flexibility, cost, and performance that the edge can deliver. IDC estimates that global spending on edge hardware, software and services will top $176 billion in 2022—a 14.8% increase over the prior year—reaching $274 billion by 2025. So it’s likely that your developers are either working on edge applications now or will be in the near future.
Before you dive in, however, there are some things to consider. My experience as an enterprise architect working with development organizations has taught some important lessons for creating edge applications. Keeping these lessons in mind can help you avoid frustrating outcomes and ensure you take full advantage of what the edge has to offer.
Lesson 1: Challenge Your Thinking
Too often, developers approach creating edge apps as if they were just like apps for the data center or the cloud. But the edge is a different paradigm, requiring a different approach to writing code—and a thoughtful approach to selecting which applications are right for the edge.
Most developers are used to centralized computing environments that have a large amount of compute resources in a small number of servers. But edge computing flips this around, having relatively modest resources distributed across many servers in disparate locations. This can impact the scalability of any one edge workload. So, for example, an application that uses a lot of memory may not scale well across hundreds or thousands of edge instances. For this reason, most edge apps will be purpose-built for the edge rather than “lift and shift” from an existing data center or cloud deployment.
You need to think critically about how an edge architecture impacts your application and which applications will benefit from this distributed approach. It’s usually easier to bring logic to where the data is. So if the data is more regionalized or requires access to large, centralized data stores, a cloud-based approach might make sense. But when an application is using data generated at the edge—such as request/response, cookies and headers coming from an online user—that’s where edge compute can really shine.
Lesson 2: Don’t Overlook the Basics

(metamorworks/Shutterstock)
While distributing code to the edge can improve latency and scalability, it will not magically run faster. Inefficient code will be just as inefficient at the edge. As discussed, each point of presence at the edge will be more resource-constrained than a typical centralized compute environment—especially in a serverless edge environment. When writing code for the edge, optimizing efficiency is crucial to gain the full benefit of this architecture.
When pushing functionality to the edge is relatively quick and easy, you still need to apply the same diligent management processes that you would typically employ with any code. This includes good change management processes, storing code in source control and using code reviews to evaluate code quality.
Lesson 3: Rethink Scalability
With the edge, you are “scaling out” rather than “scaling up.” So instead of thinking in terms of per-server constraints, you need to develop code to fit per-request constraints. These include constraints on memory usage, CPU cycles and time per request. Constraints will vary depending on which edge platform you’re using, so it’s important to be aware of them and design your code accordingly.
In general, you’ll want to operate with the minimal dataset required for each operation. For example, if you are doing A/B testing at the edge, you would only want to store the subset of data required for the specific request or page you’re operating with, rather than the entire set of rules. For a location-based experience, you would only have data for a specific state or region being served by that edge instance in a lightweight lookup, rather than the data for all regions.
Lesson 4: Code for Reliability
Ensuring the reliability of edge applications is absolutely essential for delivering a positive user experience. Make sure to include testing edge code in your QA plan. Adding proper error handling is also important to ensure your code can gracefully handle errors, including planning and testing fallback behavior in the event occurs. For example, if your code exceeds the constraints imposed by the platform, you will want to create a fallback to some default content so the user does not receive an error message that would impact their experience.

Constraints vary with the hardware, so design your edge solution accordingly
Performing distributed load testing is a good practice to confirm your app’s scalability. And once you deploy your code, continue to monitor the platform to ensure you don’t exceed CPU and memory limitations and to keep track of any errors.
Lesson 5: Optimize Performance
The key benefit of edge computing is the dramatic reduction in latency by moving data and compute resources close to the user. Creating lightweight, efficient code is crucial to achieving this benefit as you scale across hundreds or thousands of points of presence (PoPs). Data required to complete a function should also be at the edge. Developing code that requires fetching data from a centralized data store would erase the latency advantage offered by edge.
The same emphasis on efficient execution goes for any third-party code you might want to leverage for your edge application. Some existing code libraries are inefficient, hurting performance and/or exceeding the edge platform’s CPU and memory limitations. So carefully evaluate any code before incorporating it in your edge deployment.
Lesson 6: Don’t Reinvent the Wheel
While the edge is a new paradigm, that doesn’t mean you have to write everything from scratch. Most edge platforms integrate with a variety of content delivery network (CDN) capabilities, allowing you to create custom logic that generates an output that signals existing CDN features, like caching.
It’s also a good idea to architect your code to be reusable, so it can be executed both at the edge an in centralized compute environments. Abstracting core functionality into libraries that do not rely on browser, Node.JS, or specific platform features allows code to be “isomorphic,” able to run on client, server and at the edge.
Using existing open source libraries is another way to avoid rewriting common features. But watch out for libraries that require Node.JS or browser features. And consider partnering with third-party developers that integrate with the edge platform you are using, which can save time and effort, while offering the advantage of proven interoperability.
Putting the Lessons into Practice
To illustrate the impact of these best practices, consider a real-world case of an organization that had difficulties implementing a geofencing application at the edge. They were experiencing a high error rate caused by exceeding the CPU and memory limits of the platform.
Looking at how they built their application, they had data for all geo-fenced areas, 900KB of JSON, stored in each of their edge PoPs. A CPU-intensive algorithm was used to check a point of interest against each geofence, triggering a CPU timeout when the point of interest was not found in the first few areas checked.
To rectify the problem, data for each geo-fenced area was moved to a key-value store (KVS), with each area stored in a separate entry. A lightweight check was added to determine likely “candidate areas” (typically 1 to 3 candidates) for a point of interest. Full data and CPU-intensive checks were performed only on the candidate areas, dramatically reducing the CPU workload. These changes reduced the error rate to negligible levels, while improving initialization time and reducing memory usage, as shown in the figures below.
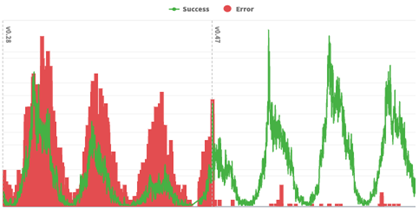
Fig 1: Before and after comparison of success and error rates (Note that success and error metrics are on different scales, thus are not directly comparable).
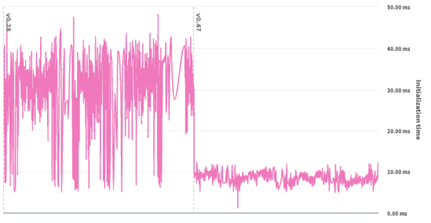
Fig 2: Before and after comparison of initialization time
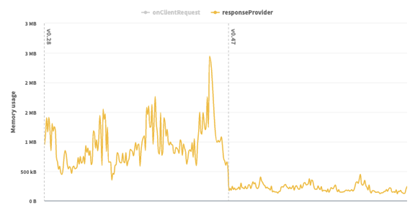
Fig 3: Before and after comparison of memory usage (Image sources: Akamai)
Making the Most of the Edge
Edge computing offers tremendous advantages for applications that benefit from being close to users, providing personalized user experiences with speed and efficiency. The keys to success are making sure your application is a good candidate for the edge and then optimizing your code to take full advantage of edge platform capabilities while working within its constraints.
Pay attention to the lessons I’ve learned working with organizations and you can achieve the full promise of the edge with greater speed—and without headaches.
About the author: Josh Johnson is a senior enterprise architect at Akamai, the content delivery network (CDN) and edge solutions provider.
This article originally appeared in Datanami.

